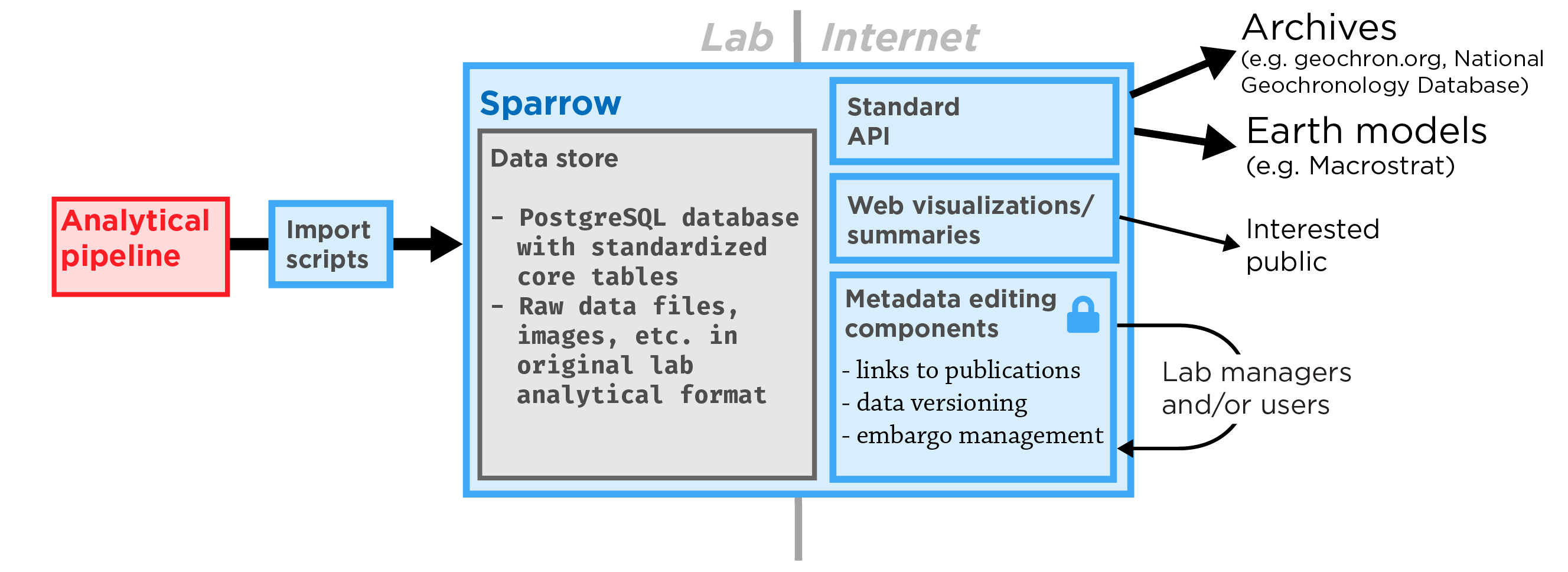
A lab information management system
Sparrow is software for managing the geochemical data created by an individual geochronology laboratory. It is designed for flexibility and extensibility, so that it can be tailored to the needs of individual analytical labs that manage a wide variety of data.
An interface to the community
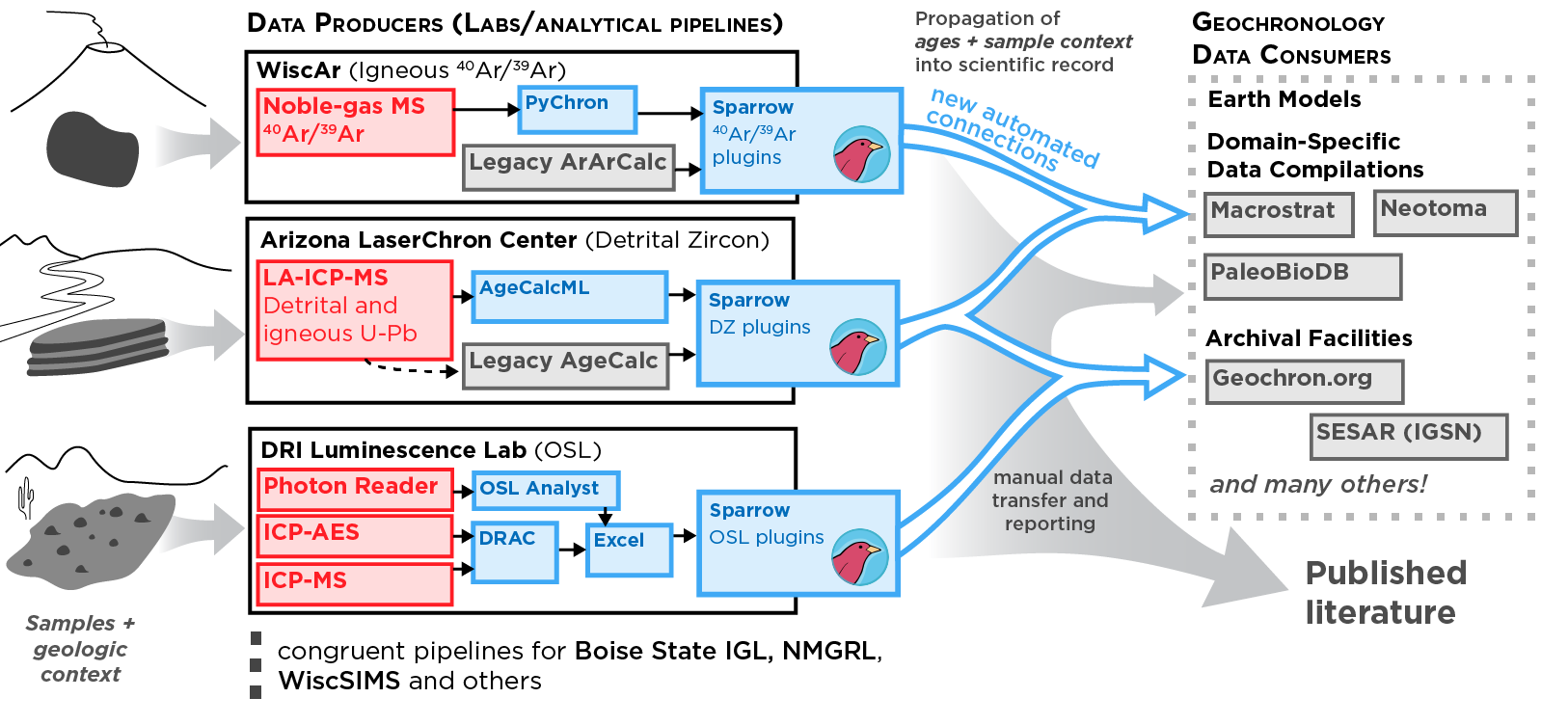
When data is created at an analytical lab, it is archived internally by the lab itself. However, it must also be interpreted by outside researchers, integrated into publications, and archived in publication records and global databases. This process is time-consuming for labs, which would like to focus on their core competency of zapping rocks.
Our hope is that a well architected, lab-managed data store with a standardized basic schema and web-facing API will provide a flexible and extensible way to automate connections to the community.
Modes of access
We intend to provide several modes of data access to ease parts of this process.
A project-centric web user interface, managed by the lab and possibly also the researcher. We hope to eventually support several interactions for managing the lifecycle of analytical data:
- Link literature references to laboratory archival data
- Manage sample metadata (locations, sample names, etc.)
- Manage data embargo and public access
- Visualize data (e.g. step-heating plots, age spectra)
- Track measurement versions (e.g. new corrections)
- Download data (for authors' own analysis and archival purposes)
Getting data in and out
On the server, direct database access and a command line interface will allow the lab to:
- Upload new and legacy data using customized scripts
- Apply new corrections without breaking links to published versions or raw data
- Run global checks for data integrity
- Back up the database
A web frontend will allow users outside the lab to
- Access data directly from the lab through an API for meta-analysis
- Browse a snapshot of the lab's publicly available data, possibly with data visualizations.
Finally, a standardized API will allow third parties to pull the lab's public data into other endpoints, such as Geochron.org and Macrostrat.
Place within the lab
This software is designed to run on a standard virtualized
UNIX server with a minimum of setup and intervention, and outside
of the data analysis pipeline.
It will be able to accept data from a variety of data
management pipelines through simple import scripts. Generally,
these import scripts will be run on an in-lab machine with access
to the server. Data collection, storage, and analysis tools
such as PyChron
sit immediately prior to this system in a typical lab's data production pipeline.
Meta-goals
- Train lab workers in managing their data in a more powerful way
- Emphasize the power of scientists taking control of their own software
Design
We want this software to be useful to many labs, so a strong and flexible design is crucial. Sparrow will have an extensible core with well-documented interfaces for pluggable components. Key goals from a development perspective will be a clear, concise, well-documented and extensible schema, and a reasonably small and stable code footprint for the core functionality, with clear "hooks" for lab specific functionality.
Sparrow's technology stack consists of several parts:
- a Python-based API server
sqlalchemyfor database accessFlaskweb-application framework
- PostgreSQL database backend
- configurable and extensible schema
- stateless schema migrations with
migra
React-based administration interface- Managed with
gitwith separate branches for analytical types and individual labs. - Software packaged primarily fro lightweight, containerized (e.g. Docker) instances.
Code and issues for this project are tracked on Github.
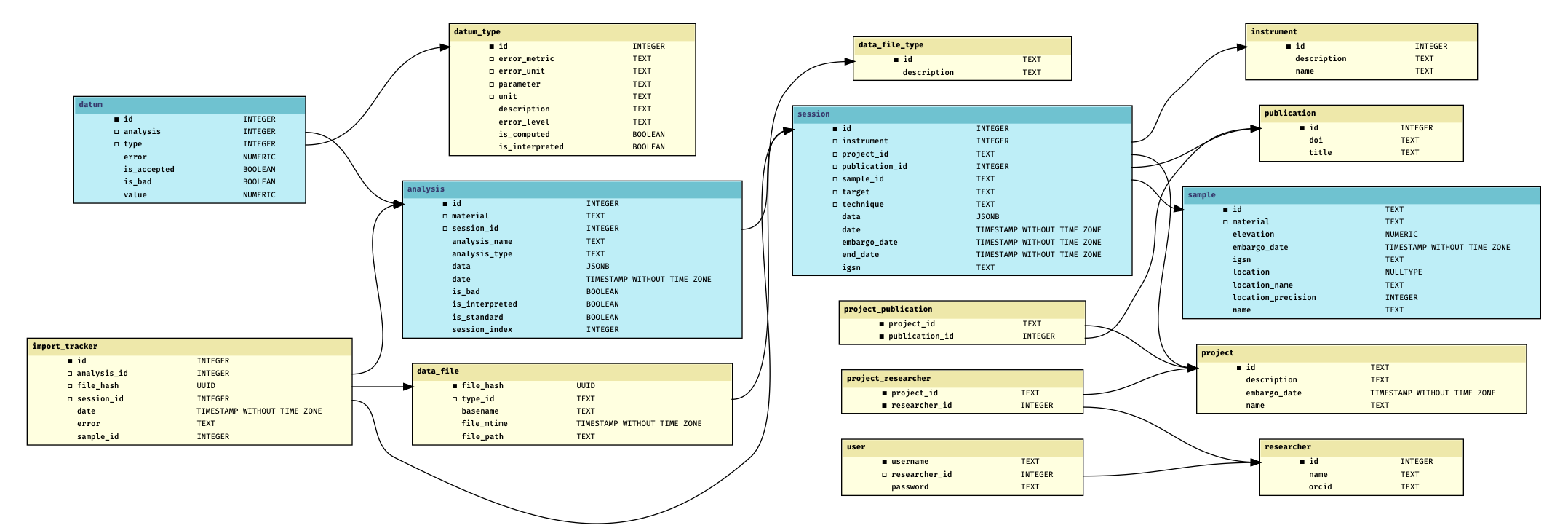
Data model
Hierarchical levels of analytical data
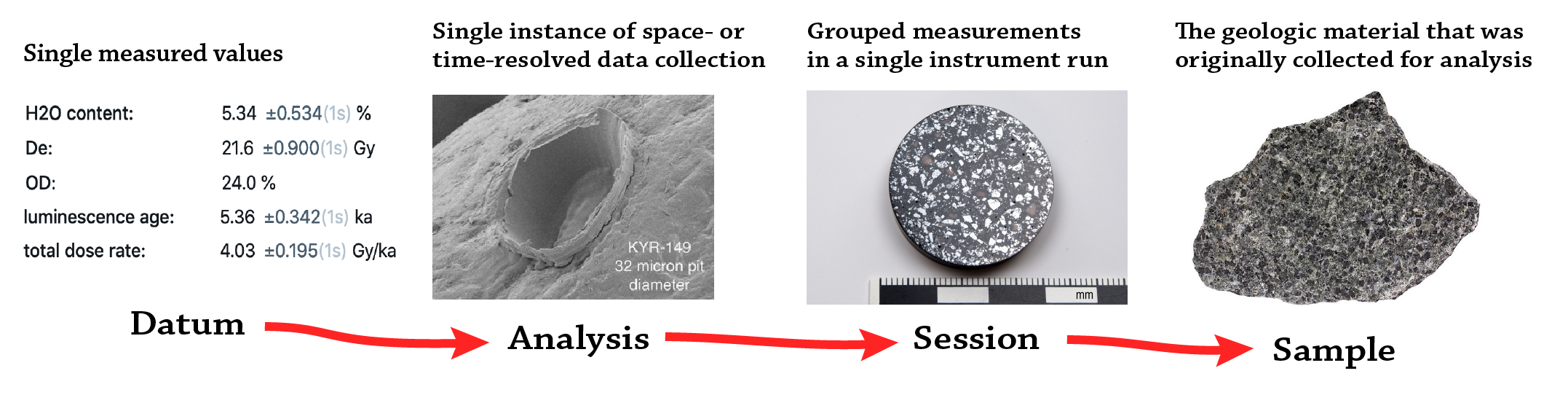
datum: an individual data point (any numerical parameter and its error)analysis: an collection of data points measured at the same time (roughly synonymous with aliquot)session: a set of measurements conducted on the same sample at the same timesample: A geological sample
Database schema
- A data-storage schema to store heterogeneous geochronology data
- Flexible to store lab-specific data shapes
- A common core of standardized tables
- Standard vocabularies to manage meaning
Data must be loaded into this standardized core in order to be exposed to the outside world.
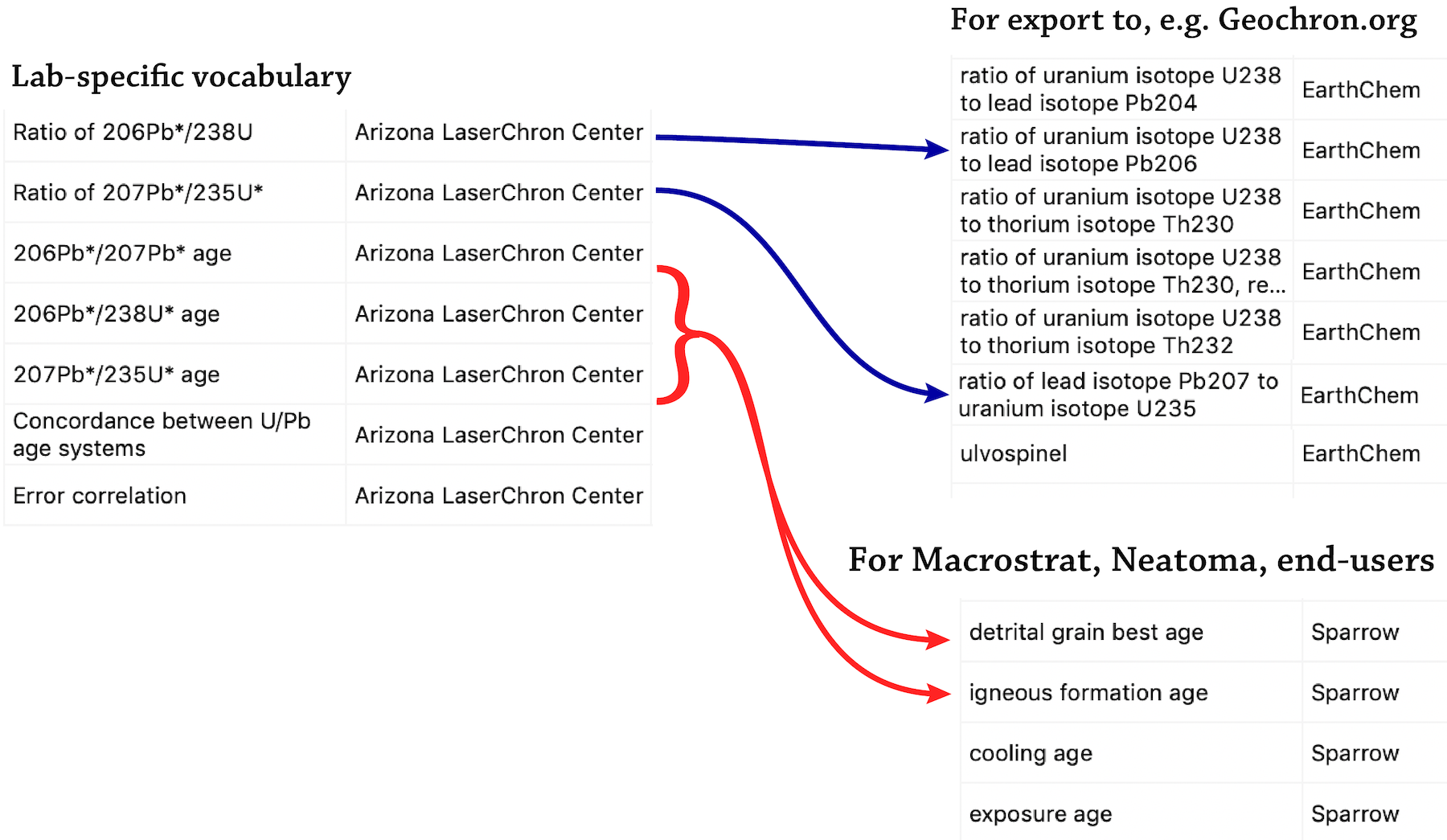
Schema → API
The Sparrow API will map lab-specific vocabulary to community standards.